Standardizing the Evaluation of Usability Test Results: Criteria Development and Human-AI Collaborative Performance
Abstract
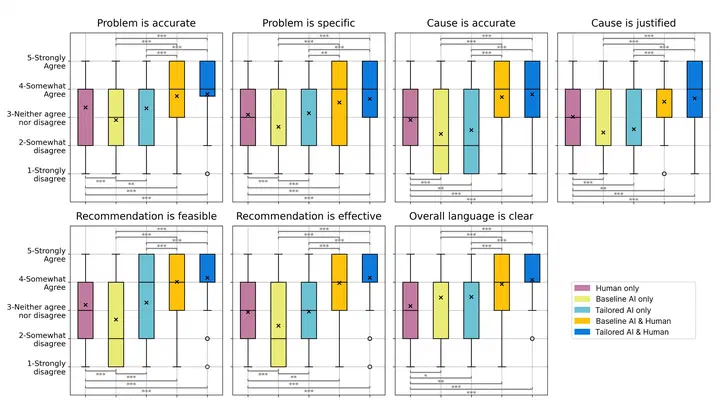
The growing use of artificial intelligence (AI) across industries has spurred interest in its application to usability analysis. Yet, standardized criteria for evaluating AI-generated usability test results are lacking, and the impact of strategies such as role prompting and human review on the quality of results remains underexplored. To address these gaps, we first developed seven evaluation criteria grounded in user experience (UX) literature and a survey of 40 UX professionals. Second, we recruited UX experts to apply these criteria to usability findings generated under five conditions: human-only, baseline AI-only, tailored AI-only, baseline AI with human review, and tailored AI with human review. Expert evaluations show that human-AI collaboration, especially tailored AI combined with human review, produced significantly higher-quality results than either humans or AI alone. These findings provide practical methodologies and empirical evidence to support human-AI collaboration in usability analysis, informing system design for complex human–computer interaction tasks.